Activity: Input#
The input structure of nJAMS activities allows you to map additional content to nJAMS. Since all elements of the input structure are optional it is not required to provide input for any field.
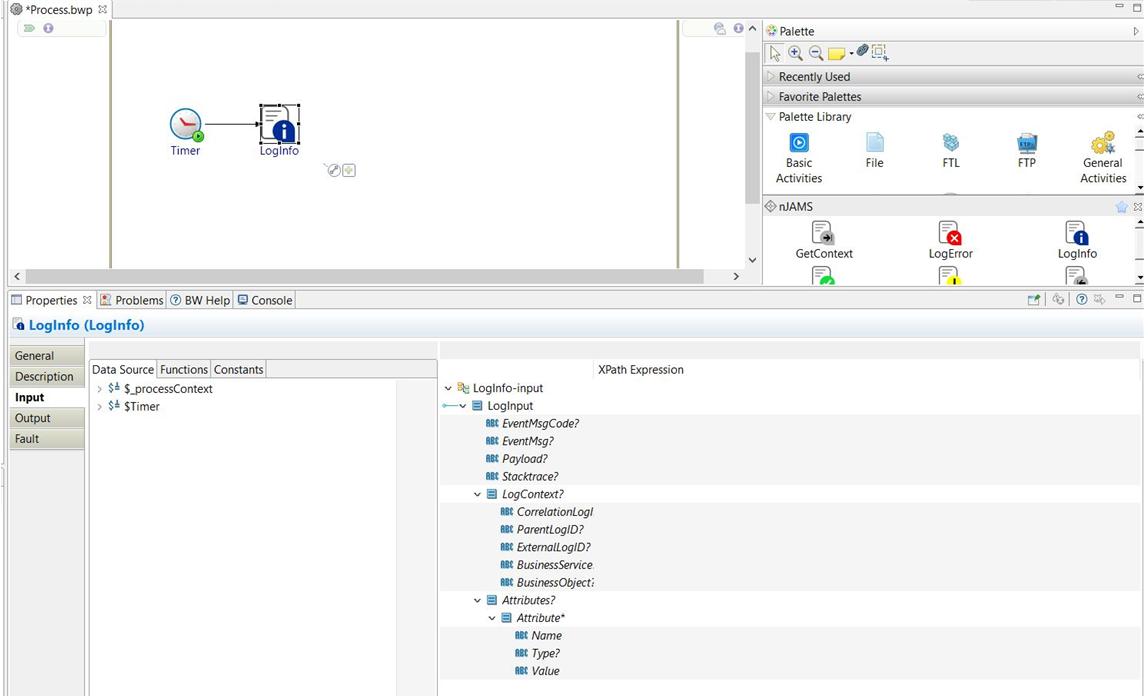
The following fields are available:
Element |
Datatype |
max length |
Description |
|---|---|---|---|
EventMsgCode |
string |
1000 byte [1] |
User defined log message code id. |
EventMsg |
string |
1000 byte [1] |
User defined log message name such as description of the event, postition of the event, etc. |
Payload |
string |
unlimited [2] |
Ths is the payload message transported by the process. |
Stacktrace |
string |
unlimited [2] |
The stacktrace object contains technical error information. This element is especially suitable for activity LogError. |
Attributes |
This element contains information that can be mapped individually. Typically attributes contain business related content like order number, customer name, etc. |
||
Attribute |
This is the repeating element. |
||
Name |
string |
1000 byte [1] |
The name of an attribute describes meaning of the content. |
Type |
string |
100 byte [1] |
You can declare a specific type of the attribute like “string”, “number”, “date”. This element is optional. If not provided, a string will be assumed. |
value |
string |
4000 byte [1] |
The attribute value contains the data of the attribute. For example if attribute type is “OrderId”, a valid content might be “A4711”. |
LogContext |
|||
CorrelationLogID |
string |
1000 byte [1] |
This Id is used by nJAMS to correlate multiple log entries to a log entry chain. |
ParentLogID |
string |
1000 byte [1] |
This ID allows a hierarchical composition of log entries. The ParentLogID is the LogID of the process instance that calls the current process. |
ExternalLogID |
string |
1000 byte [1] |
This ID is a user defined identifier. |
BusinessService |
string |
1000 byte [1] |
Name of the Business Service that is represented by one or more technical processes. |
BusinessObject |
string |
1000 byte [1] |
Name of the Business Object that is delivered by one or more technical processes. |